A New Dataset


We introduce a new dataset named Semantic-HOI, which provides fine-grained descriptions for HOI states and the body movement between two consecutive states.
We introduce a new dataset named Semantic-HOI, which provides fine-grained descriptions for HOI states and the body movement between two consecutive states.
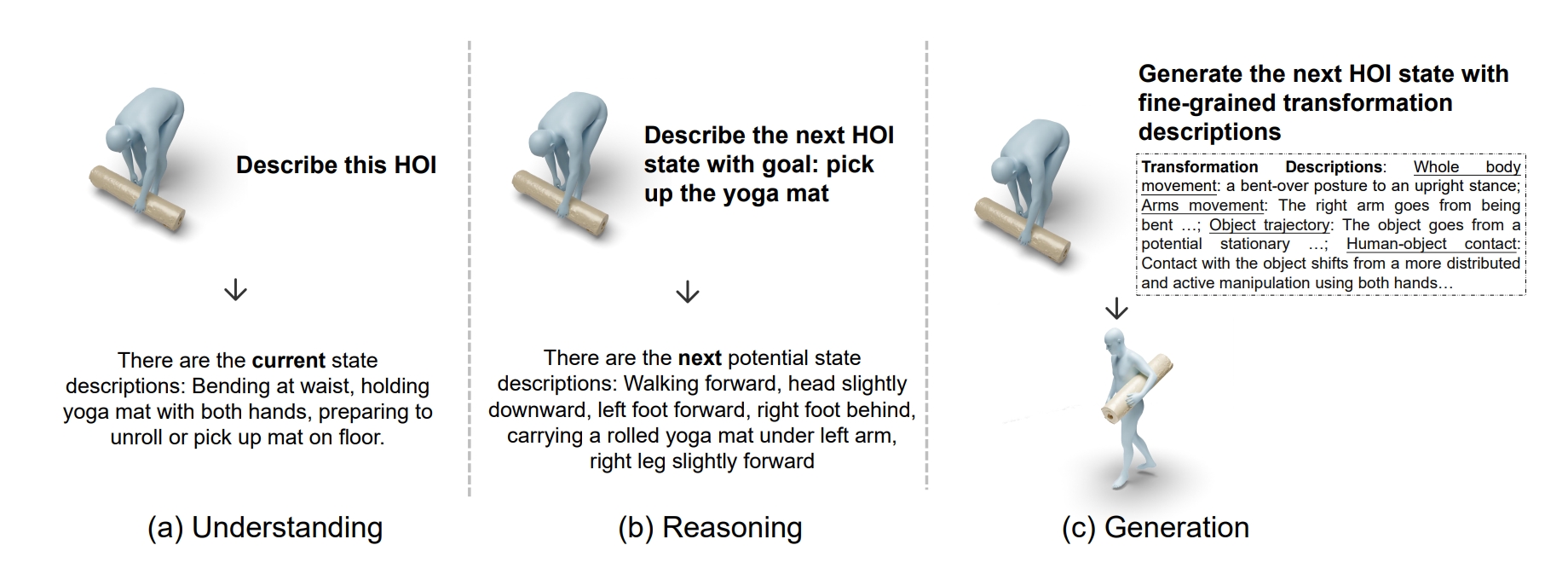
We define three new state-level HOI tasks from the perspectives of understanding, reasoning, and generation, to demonstrate fine-grained semantic-aligned HOI modeling.
Existing 3D human object interaction (HOI) datasets and models simply align global descriptions with the long HOI sequence, while lacking a detailed understanding of intermediate states and the transitions between states. In this paper, we argue that fine-grained semantic alignment, which utilizes state-level descriptions, offers a promising paradigm for learning semantically rich HOI representations. To achieve this, we introduce Semantic-HOI, a new dataset comprising over 20K paired HOI states with fine-grained descriptions for each HOI state and the body movements that happen between two consecutive states. Leveraging the proposed dataset, we design three state-level HOI tasks to accomplish fine-grained semantic alignment within the HOI sequence. Additionally, we propose a unified model called F-HOI, designed to leverage multimodal instructions and empower the Multi-modal Large Language Model to efficiently handle diverse HOI tasks. F-HOI offers multiple advantages: (1) It employs a unified task formulation that supports the use of versatile multimodal inputs. (2) It maintains consistency in HOI across 2D, 3D, and linguistic spaces. (3) It utilizes fine-grained textual supervision for direct optimization, avoiding intricate modeling of HOI states. Extensive experiments reveal that F-HOI effectively aligns HOI states with fine-grained semantic descriptions, adeptly tackling understanding, reasoning, generation, and reconstruction tasks.
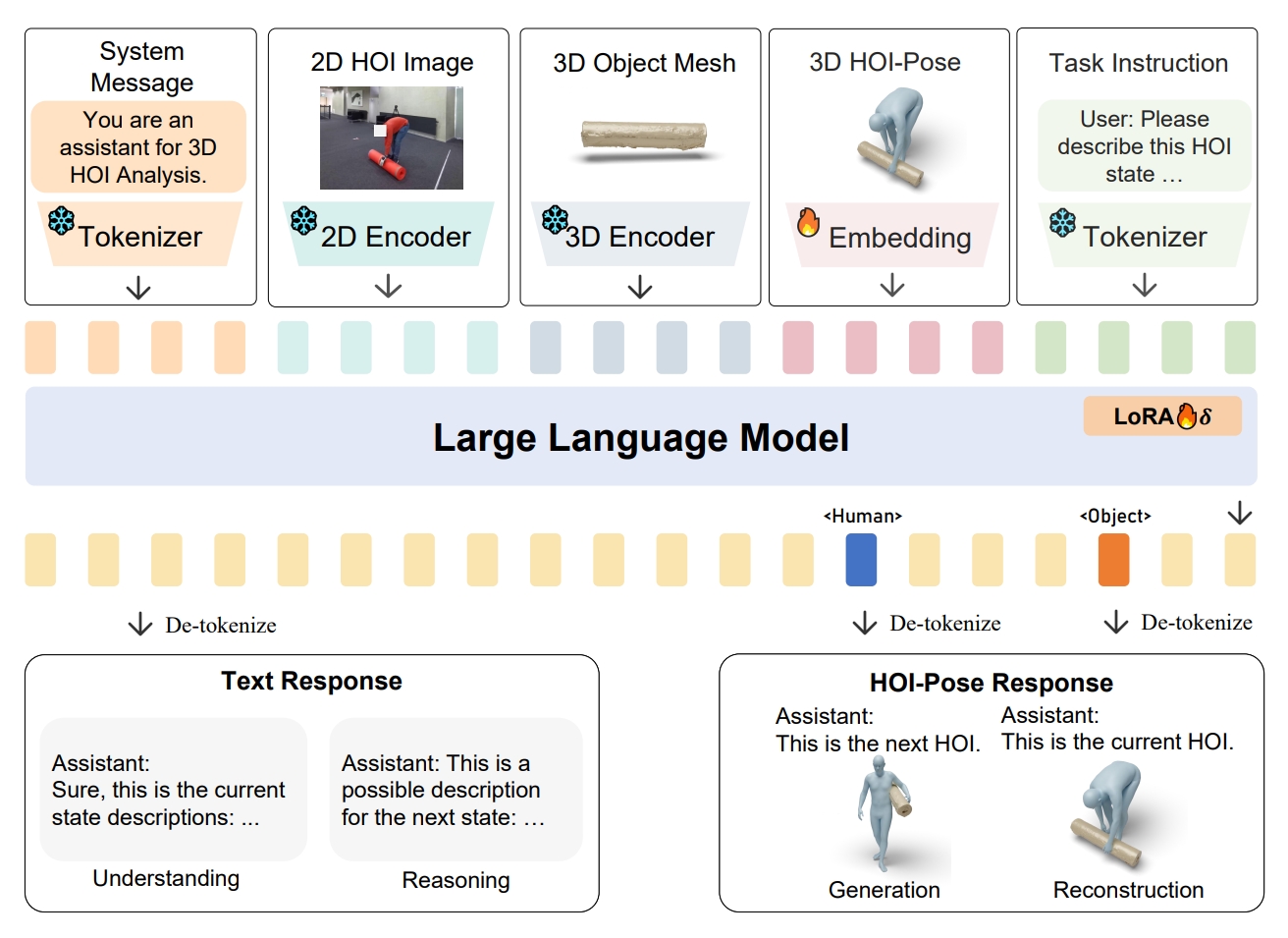
Overview of our F-HOI framework, which contains the three components: multimodal encoders, a large language model, and task-specific projectors. Based on different task instructions, F-HOI could support multi-modal inputs and complete diverse HOI tasks, covering understanding, reasoning, generation and reconstruction tasks.

We show the potential of fine-grained descriptions in controlling changes in human-object interactions.
@article{yang2024fhoi,
title={F-HOI: Toward Fine-grained Semantic-Aligned 3D Human-Object Interactions},
author={Yang, Jie and Niu, Xuesong and Jiang, Nan and Zhang, Ruimao and Siyuan, Huang},
journal={European Conference on Computer Vision},
year={2024}
}